LAMBADA Dataset Papers With Code
Von einem Mystery-Man-Autor
Last updated 01 Juni 2024

The LAMBADA (LAnguage Modeling Broadened to Account for Discourse Aspects) benchmark is an open-ended cloze task which consists of about 10,000 passages from BooksCorpus where a missing target word is predicted in the last sentence of each passage. The missing word is constrained to always be the last word of the last sentence and there are no candidate words to choose from. Examples were filtered by humans to ensure they were possible to guess given the context, i.e., the sentences in the passage leading up to the last sentence. Examples were further filtered to ensure that missing words could not be guessed without the context, ensuring that models attempting the dataset would need to reason over the entire paragraph to answer questions.
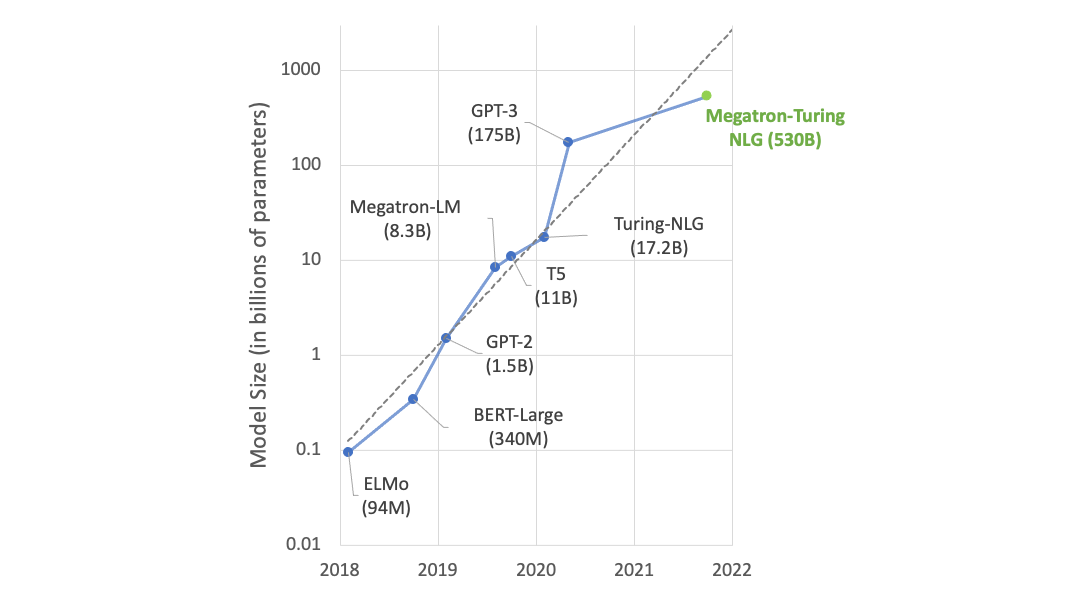
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B
Machine Learning Datasets

ClueWeb22 Dataset
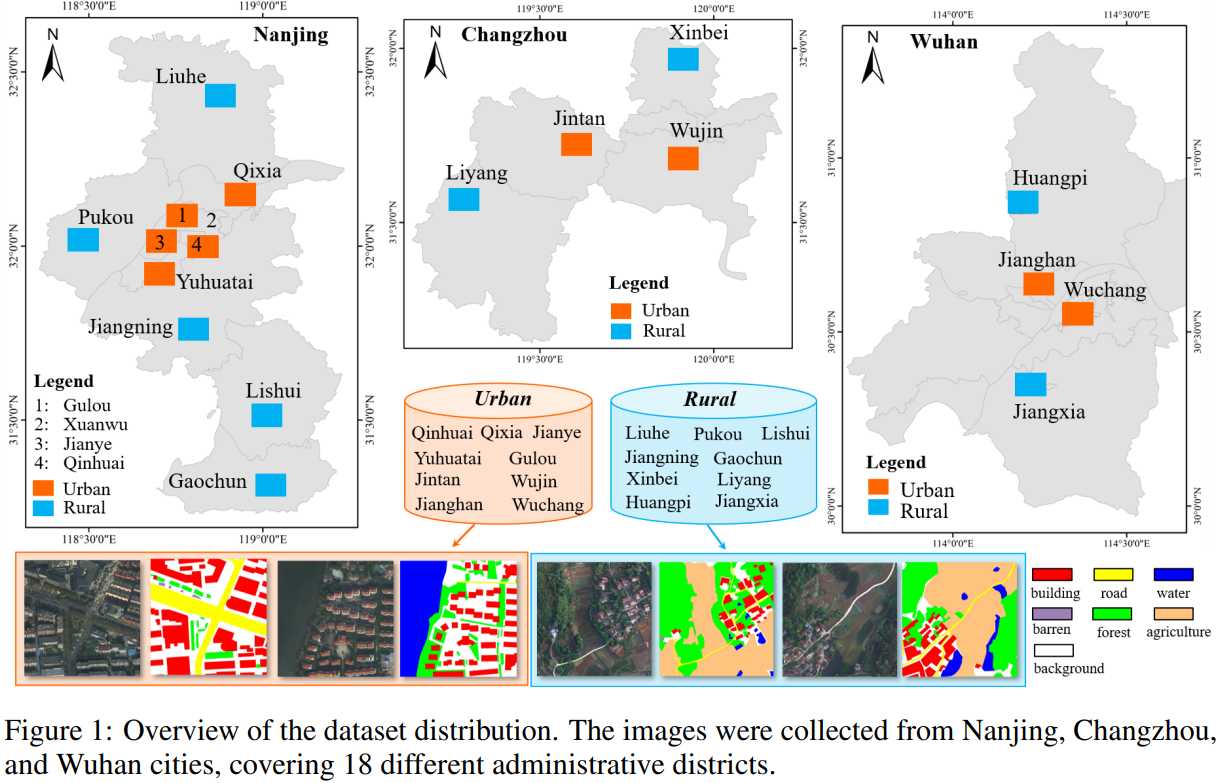
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive
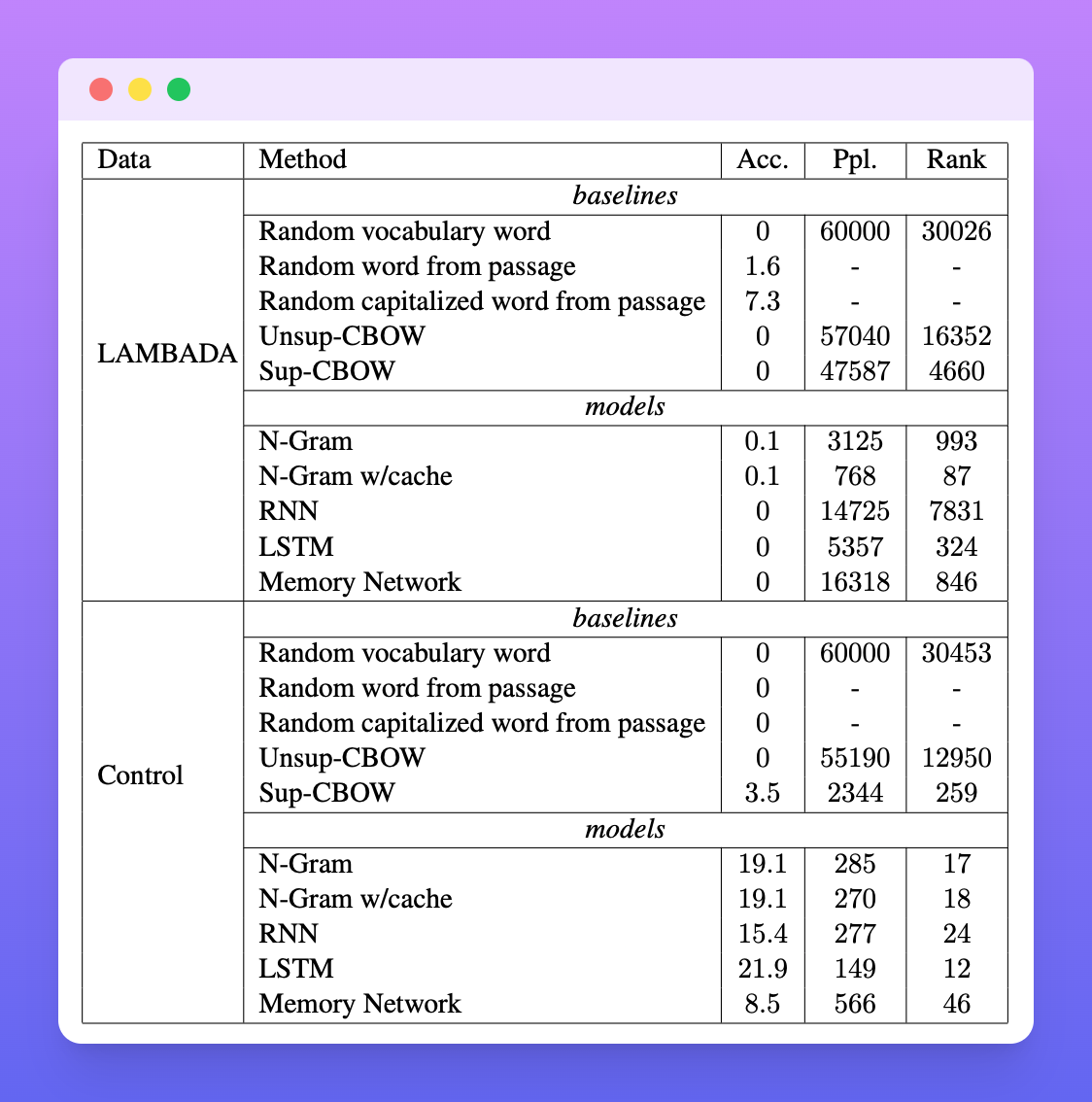
Two minutes NLP — Keeping track of information and the LAMBADA

Paper page - Stay on topic with Classifier-Free Guidance
Foundation Models for Text Generation

LAMBADA Benchmark (Language Modelling)

2022-7-17 arxiv roundup: Next-ViT, Anthropic & DeepMind & Google

A Survey of Large Language Models
für dich empfohlen
 LargeUp Premiere: Do the Lambada with Elephant Man + Serocee14 Jul 2023
LargeUp Premiere: Do the Lambada with Elephant Man + Serocee14 Jul 2023 Stream Kaoma - Lambada (LMSam HT Rework) by SINDEX14 Jul 2023
Stream Kaoma - Lambada (LMSam HT Rework) by SINDEX14 Jul 2023 Dançando Lambada - Wikipedia14 Jul 2023
Dançando Lambada - Wikipedia14 Jul 2023 Lagoa – Lambada Suave (Vinyl) - Discogs14 Jul 2023
Lagoa – Lambada Suave (Vinyl) - Discogs14 Jul 2023 Lambada sheet music for piano solo (chords, lyrics, melody) (PDF)14 Jul 2023
Lambada sheet music for piano solo (chords, lyrics, melody) (PDF)14 Jul 2023 LA LAMBADA STROFINERA Sheet music14 Jul 2023
LA LAMBADA STROFINERA Sheet music14 Jul 2023 Tulpe Lambada von Peter Nyssen Blumenzwiebeln und Pflanzen14 Jul 2023
Tulpe Lambada von Peter Nyssen Blumenzwiebeln und Pflanzen14 Jul 2023 Lambada – Voice & Style Expansion Packs for Yamaha Genos - Tyros 5 - PSR series14 Jul 2023
Lambada – Voice & Style Expansion Packs for Yamaha Genos - Tyros 5 - PSR series14 Jul 2023![Forbidden Dance Is Lambada [Import USA Zone 1]: : DVD & Blu-ray](https://m.media-amazon.com/images/I/61g0A55UhyL._AC_UF894,1000_QL80_.jpg) Forbidden Dance Is Lambada [Import USA Zone 1]: : DVD & Blu-ray14 Jul 2023
Forbidden Dance Is Lambada [Import USA Zone 1]: : DVD & Blu-ray14 Jul 2023 Lambada® Kordes Rosen14 Jul 2023
Lambada® Kordes Rosen14 Jul 2023
Sie können auch mögen
 Druckschlauch Kompressorschlauch Druckluftschlauch PVC 5/16 8x13mm 100 Meter14 Jul 2023
Druckschlauch Kompressorschlauch Druckluftschlauch PVC 5/16 8x13mm 100 Meter14 Jul 2023 China Custom AMG Aufkleber Hersteller, Lieferanten - Fabrik Direkt14 Jul 2023
China Custom AMG Aufkleber Hersteller, Lieferanten - Fabrik Direkt14 Jul 2023 All-Weather Floor Mats (High-Wall)14 Jul 2023
All-Weather Floor Mats (High-Wall)14 Jul 2023 HIGH QUALITY NEW Style Cable Car Black ABS Adapter Car Accessories14 Jul 2023
HIGH QUALITY NEW Style Cable Car Black ABS Adapter Car Accessories14 Jul 2023 Auto-K Füllspachtel + Härter 250 g Spachtel Spachtelmasse14 Jul 2023
Auto-K Füllspachtel + Härter 250 g Spachtel Spachtelmasse14 Jul 2023 Hyundai Tucson 2019 2.0 CRDI LIMITED 2.014 Jul 2023
Hyundai Tucson 2019 2.0 CRDI LIMITED 2.014 Jul 2023 Auto Toter Winkel Spiegel 360 Grad Rotation Auto rahmenlos Kleine14 Jul 2023
Auto Toter Winkel Spiegel 360 Grad Rotation Auto rahmenlos Kleine14 Jul 2023 Edelstahl Frontbügel Frontschutzbügel für Nissan Qashqai 2018-2021 Gra14 Jul 2023
Edelstahl Frontbügel Frontschutzbügel für Nissan Qashqai 2018-2021 Gra14 Jul 2023 Bb Klarinette Uebel Serie 2 mit Koffer und 2. Birne guter Zustand14 Jul 2023
Bb Klarinette Uebel Serie 2 mit Koffer und 2. Birne guter Zustand14 Jul 2023 BLUES BROTHERS SET Hut und Brille Kostümset Mafia Gangster Karneval EUR 7,99 - PicClick DE14 Jul 2023
BLUES BROTHERS SET Hut und Brille Kostümset Mafia Gangster Karneval EUR 7,99 - PicClick DE14 Jul 2023